https://www.hanbit.co.kr/store/books/look.php?p_code=B6846155853
혼자 공부하는 SQL
데이터베이스 개념부터 SQL 문법까지 입문자의 눈높이에 맞춰 구성했습니다. 지루한 설명 대신 도식화된 이미지와 예제를 통한 실습으로 책의 마지막까지 흥미롭게 학습할 수 있습니다. 프로그
www.hanbit.co.kr
위 내용은 <혼자 공부하는 SQL>을 기반으로 공부하여 작성 내용입니다.
6-1 인덱스 개념을 파악하자
- 인덱스(index) : 데이터를 빠르게 찾을 수 있도록 도와주는 도구
- 클러스터형 인덱스(Clustered Index)
- 기본키로 지정하면 자동 생성되며 테이블에 1개만 만들 수 있음
- 기본 키로 지정한 열을 기준으로 자동 정렬됨
- 보조 인덱스(Secondary Index)
- 고유 키로 지정하면 자동 생성됨
- 여러 개를 만들 수도 있지만 자동 정렬되지 않음
인덱스의 개념
- 데이터의 양이 적을 때는 인덱스가 없어도 문제가 되지 않음
- 데이터가 많아지면 데이터가 어디에 있는지 찾기 힘듦
- 데이터를 찾을 때, 인덱스의 사용 여부에 따른 결과값의 차이는 없음
인덱스의 문제점
- 인덱스를 제대로 이해하지 못한 채 남용하면 안됨
- 필요 없는 인덱스를 만들면 데이터베이스에 차지하는 공간만 더 늘어남
- 인덱스를 이용해서 데이터를 찾는 것이 전체 테이블을 찾아보는 것보다 느려짐
똑똑한 MySQL
- 데이터베이스에 인덱스를 생성해 놓아도, 인덱스를 사용해서 검색하는 것이 빠를지 아니면 전체 테이블을 검색하는 것이 빠를지 MySQL이 알아서 판단함.
- 만약 인덱스를 사용하지 않는다면 사용하지도 않는 찾아보기를 만든 것이므로 쓸데 없이 공간을 낭비한 것
인덱스의 장점과 단점
장점
- SELECT 문으로 검색하는 속도가 매우 빨라짐
- 그 결과 컴퓨터의 부담이 줄어들어서 결국 전체 시스템의 성능이 향상됨
단점
- 인덱스도 공간을 차지해서 데이터베이스 안에 추가적인 공간이 필요
- 인덱스는 대략 테이블 크기의 10% 정도의 공간이 추가로 필요
- 처음에 인덱스를 만드는 데 시간이 오래 걸릴 수 있음
- SELECT가 아닌 데이터의 변경 작업(INSERTM UPDATE, DELETE)이 자주 일어나면 오히려 성능이 나빠질 수도 있음
인덱스의 종류
- 클러스터형 인덱스 -> 영어사전처럼 책의 내용이 이미 알파벳 순서대로 정렬됨
- 보조 인덱스 -> 책과 같이 찾아보기가 별도로 있고, 찾아보기에서 해당 단어를 찾은 후에 옆에 표시된 페이지를 펼쳐야 실제 찾는 내용 있음
자동으로 생성되는 인덱스
- 3장에서 회원 테이블 정의 시 사용한 SQL문
USE market_db;
CREATE TABLE member -- 회원 테이블
( mem_id CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(PK)
mem_name VARCHAR(10) NOT NULL, -- 이름
mem_number INT NOT NULL, -- 인원수
addr CHAR(2) NOT NULL, -- 지역(경기,서울,경남 식으로 2글자만입력)
phone1 CHAR(3), -- 연락처의 국번(02, 031, 055 등)
phone2 CHAR(8), -- 연락처의 나머지 전화번호(하이픈제외)
height SMALLINT, -- 평균 키
debut_date DATE -- 데뷔 일자
);- mem_id를 기본 키로 정의함 -> 자동으로 mem_id 열에 클러스터형 인덱스 생성
- 단, 테이블에 한 개만 만들 수 있음
use market_db;
create table table1 (
col1 int primary key, -- 기본 키로 지정
col2 int,
col3 int
);
show index from table1
- Key_name 부분을 보면 PRIMARY라고 적혀있음 -> '자동으로 생성된 인덱스'라는 의미
- Column_nam이 col1로 설정됨 -> col1 열에 인덱스가 만들어져 있음
- Non_Unique -> '고유하지 않음' -> 중복이 허용되지 않음 (중복이 허용되는지 확인)
- Non_Unique = 0 : False
- Non_Unique = 1 : True
- 고유 인덱스(Unique Index)는 인덱스의 값이 중복되지 않음
- 단순 인덱스(Non_Unique Index)는 인덱스의 값이 중복되어도 됨
- 기보 키나 고유 키로 지정하면 값이 중복되지 않으므로 고유 인덱스가 생성됨
use market_db;
create table table2 (
col1 int primary key,
col2 int unique, -- 고유 키로 지정
col3 int unique
);
show index from table2;
- 보조 인덱스는 고유키로 지정하면 자동으로 생성되며, 테이블당 여러 개 만들 수 있음
자동으로 정렬되는 클러스터형 인덱스
use market_db;
drop table if exists buy, member;
create table member
(
mem_id char(8),
mem_name varchar(10),
mem_numver int,
addr char(2)
);
insert into member values('TWC','트와이스', 9, '서울');
insert into member values('BLK','블랙핑크', 4, '경남');
insert into member values('WMN','여자친구', 6, '경기');
insert into member values('OMY','오마이걸', 7, '서울');
select * from member;
alter table member
add constraint
primary key(mem_id);
select * from member;
- mem_id열을 기본 키로 지정했으므로 mem_id 열에 클러스터형 인덱스가 생성되어 mem_id 열을 기준으로 정렬
alter table member drop primary key; -- 기본 키 제거
alter table member
add constraint
primary key(mem_name); -- 기본 키 설정
select * from member; -- 테이블 조회
- 기본 키 변경으로 데이터의 내용 변경은 없으나, mem_name 열을 기준으로 다시 정렬됨
- 이후로 추가로 데이터를 입력하면 알아서 기준에 맞춰 정렬됨
insert into member values('GRL', '소녀시대', 9, '서울');
select * from member;
기본 키 변경 시 주의할 점
- 이미 대용량의 데이터가 있는 상태에서 기본 키를 지정하면 시간이 엄청 오래 걸릴 수 있음
정렬되지 않은 보조 인덱스
- 테이블에 여러 개 설정 가능
drop table if exists member;
create table member
(
mem_id char(8),
mem_name varchar(10),
mem_number int,
addr char(2)
);
insert into member values('TWC','트와이스', 9, '서울');
insert into member values('BLK','블랙핑크', 4, '경남');
insert into member values('WMN','여자친구', 6, '경기');
insert into member values('OMY','오마이걸', 7, '서울');
select * from member;
- 입력한 순서 그대로 결과 나옴
alter table member
add constraint
unique(mem_id); -- 고유 키 설정
select * from member;
insert into member values('GRL', '소녀시대', 9, '서울');
select * from member;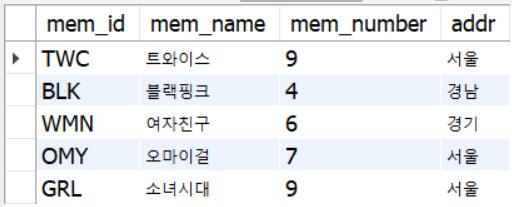
- 데이터 추가 입력 시 테이블 제일 아래에 추가됨
'SQL' 카테고리의 다른 글
| [혼자 공부하는 SQL] chapter 6. 인덱스(6-3) (0) | 2023.05.19 |
|---|---|
| [혼자 공부하는 SQL] chapter 6. 인덱스(6-2) (0) | 2023.05.18 |
| [혼자 공부하는 SQL] chapter 5. 테이블과 뷰(5-3) (0) | 2023.05.16 |
| [혼자 공부하는 SQL] chapter 5. 테이블과 뷰(5-2) (1) | 2023.05.15 |
| [혼자 공부하는 SQL] chapter 5. 테이블과 뷰(5-1) (0) | 2023.05.11 |